I recently joined the Stream Processing team at Facebook. Stream processing is overall a fairly new and very exciting space that aims to offer analytics for potentially infinite streams of data as close as possible to real time. One interesting aspect of building a stream processing system is that it requires a very deep technological stack that spans from frontend interfaces for defining stream processing pipelines; to algorithmic finesse in implementing efficient, adaptive and correct stream operators (e.g. aggregations, filters, joins) to finally a rock solid and reliable job management infrastructure to keep said pipelines up and running at all times.
I currently find myself working on the last (and lowest) of these three layers, which requires knowledge of distributed systems and job orchestration. While a lot of fun to work on and learn about, I certainly wouldn’t pretend to be an expert in these subjects. As such, it is fortunate that my team orchestrates (pun) a bi-weekly paper reading group, where we rotate among ourselves in presenting relevant papers from academia and industry that were published over the last few years. I had the pleasure of presenting the paper titled Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center a short while ago. For both knowledge sharing and personal archiving purposes I decided to write a summarizing blog post about Apache Mesos.
TL;DR
Only got 30 seconds left to read? Here is all you need to know: Mesos is a cluster management library that enables multiple independent cluster frameworks to run on the same pool of shared resources. Mesos takes the role of a resource broker, offering resources to frameworks as they become available. Scheduling tasks that use those resources, as well as starting and keeping these tasks running, is left to individual frameworks.
If you do have a bit more time to explore the details of Mesos, read on.
Background
Mesos was originally started as a research project by Benjamin Hindman (founder of Mesosphere), Andy Konwinski and Matei Zaharia (both founders of Databricks) at UC Berkeley. The original paper was published in 2011. From my diggings, it seemed the project really matured when Benjamin Hindman went to Twitter, where Mesos had to withstand the test of Twitter-scale infrastructure. Twitter still uses Mesos today, having built their internal job scheduling infrastructure on top of it. As an aside, this job scheduling infrastructure is called Apache Aurora and is open source. I’ll touch upon it towards the end of this article.
Today, Mesos is used in production by quite a plethora of companies such as Uber, Yelp, Airbnb and of course Twitter, where it all began. Apple’s Siri team reportedly uses it as well.
The Problem
Let’s start by discussing what problem Mesos was fundamentally designed to solve. The realization the Mesos paper makes in its introduction is that organizations today face computational challenges of heterogeneous nature. Gone are the days where you could dump all your data into a relational database and express each and every workload as a SQL query of some form or another. There are numerous ways to process data today, each optimized to particular workloads with particular characteristics:
- Traditional batch processing frameworks like MapReduce are best suited for offline analysis;
- Stream processing is the methodology of choice for realtime analytics on potentially infinite streams of data;
- Machine learning (ML) workloads tend to need a mix of batch and streaming, requiring yet more specialized processing.
Each of these computing paradigms comes with its own clique of software frameworks available today: From Hadoop and Hive for batch, to Storm and Flink for streaming, to Spark for ML.
The savvy organizations of today thus divide their workloads among multiple of these frameworks. While improving the efficiency of the computational work done, this poses an operational challenge. If we only use a single framework for all our processing, we can dedicate all our hardware resources to it. If we use two or more, we need to come up with a way of … sharing resources among frameworks. So, how do we do that? Easy! We simply partition our cluster (statically) into equal splits. Right?

While that would certainly work both in theory and in practice, it is likely not optimal. Say we want to use both a batch processing framework like Hadoop and a stream processing framework like Flink. We split our cluster of 100 machines in half and let all batch processing jobs run on the first 50 machines and all stream processing on the second 50 machines. It may turn out that we only run one or two batch jobs per day. These could be very heavy analytical workloads requiring all 50 machines during their operation, but they complete within one hour. This means that 22 hours of the day, the first half of our cluster is not utilized at all. This is clearly suboptimal.
One way to solve this problem is to centralize the scheduling logic of the two frameworks. If there was one scheduler to manage both our batch and streaming jobs on the same cluster, it could schedule batch and streaming jobs in tandem and scale out streaming jobs while we are not running batch jobs. Unfortunately, this idea sounds a lot better than it would turn out to be. For one, we would have to figure out how to combine the Hadoop scheduler with the Flink scheduler and generalize our centralized scheduler to handle the constraints of both. This would not only make the centralized scheduler very complex, it would also make it hard to scale to more than two frameworks.
The Big Idea
Let’s continue with our example from the previous section and examine how Mesos addresses the problem we discussed. Picture the ideal situation. Stream and batch processing jobs run alongside each other according to their requirements, keeping utilization of the cluster as high as possible. As one framework’s jobs cease operation, their resources are freed and the second framework uses them to schedule its own tasks (if necessary). Resources are shared and utilized based on demand and supply. The scheduling itself is left to the individual frameworks. This is favorable, since frameworks know best how to schedule their jobs (as opposed to a centralized scheduler). The only aspect that is managed centrally is the pool of resources. This resource sharing scheme and simultaneous use of the cluster (multiplexing) is exactly what Mesos was designed for.
Mesos likes to market iself as an operating system (OS) for data centers. This metaphor fits well. In a computer, processes compete for a shared pool of resources, such as CPU time and access to I/O devices like hard drives. These resources are managed centrally by the operating system (OS) and handed out (“brokered”) to processes as requested. In the context of Mesos and cluster computing, frameworks like Hadoop are the processes; nodes in the cluster, or more precisely their CPUs, RAM and disk space are the shared resources and the Mesos library is the operating system.
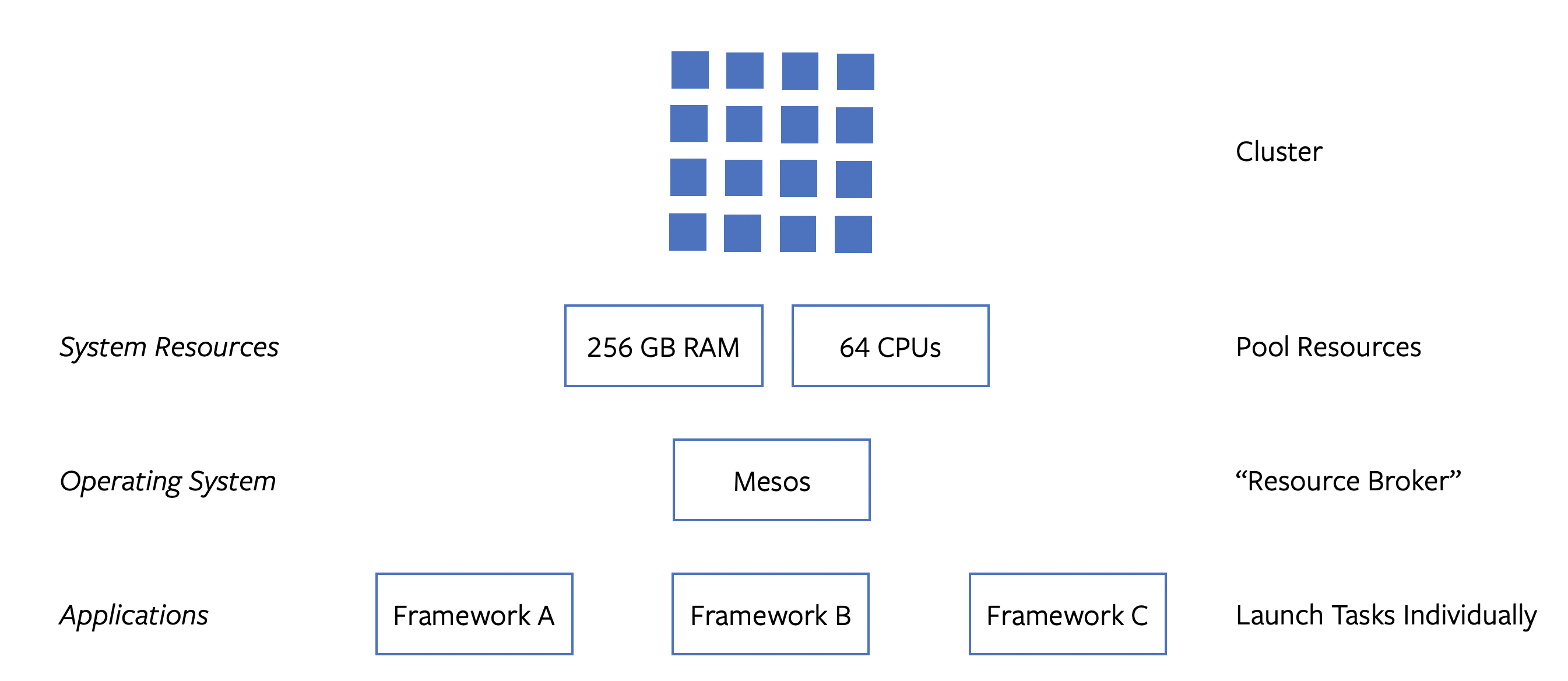
One noteworthy difference between Mesos and an OS is that an OS has more of a pull model for its resources, while Mesos uses a push model. Processes request resources and the OS fulfills those requests if possible. Mesos, by contrast, offers resources to frameworks, which then have the chance to accept them. There are some nuances to this, but I think the distinction between push and pull is an important one to mention.
Architecture
At this point, you should know that the goal of Mesos is to allow multiple frameworks to run on the same cluster simultaneously, while overseeing the sharing of computational resources among them. The big question, of course, is how Mesos does this. To answer this, let me describe the architecture of Mesos; that is, its high level building blocks and system design. The next section will then discuss the behavior of Mesos, i.e. how the components of this architecture interact.
Mesos splits its architecture into two parts: the core Mesos library, and the interfaces into which frameworks plug in. The figure below shows a birds-eye view of a typical Mesos cluster.
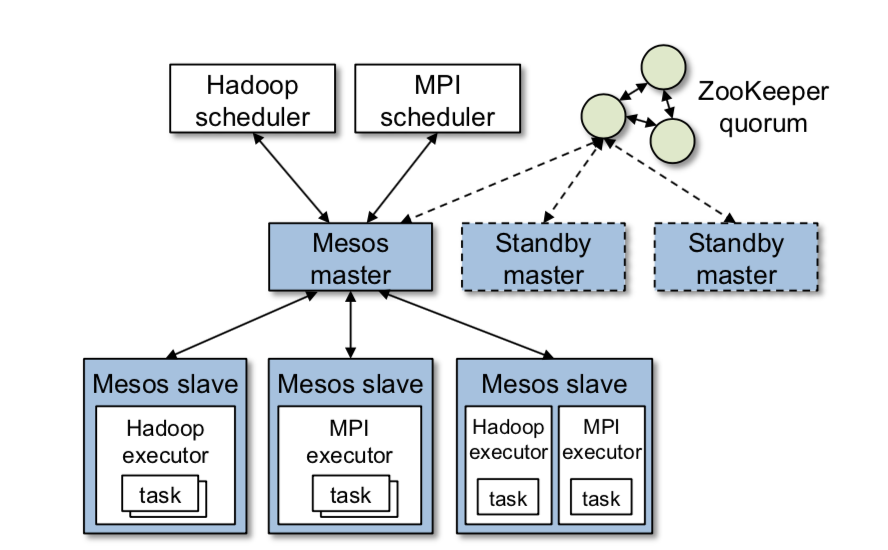
Core Mesos
The core Mesos architecture is the set of components that Mesos needs to manage a cluster and broker resources. It consists of two kinds of actors: a master node and one or more agents (a.k.a. slaves). There is one active master for the whole cluster and one agent per machine (host).
Master
The master is naturally the brain of the system. Its primary tasks include:
- Aggregating resources from individual machines in the cluster (which it gets by communicating with agents),
- Offering resources to frameworks as resources become available,
- Hosting a Web UI for humans to monitor and manage the system.
To achieve resiliency, Mesos maintains hot-standby replicas of the master and keeps exclusively soft state on each replica. Soft state here means state that is replicated elsewhere and can easily be re-materialized if the master were to go down. If the master does go down, a hot-standby can immediately take its place. To elect a new master, Mesos uses ZooKeeper to get quorum.
Agent
A Mesos Agent sits on one node in the cluster and acts as the “point of contact” for this node to the Mesos master. It:
- Supervises the execution of tasks scheduled by frameworks,
- Reports which local resources are available,
- Monitors the health of tasks running on the node and
- Manages checkpointing of tasks for fault tolerance.
Note that in this context, a task is the smallest unit of execution scheduled by a framework. For example, this would be one map or one reduce task in Hadoop. These tasks would themselves be part of a job in the framework (one MapReduce job) and there could be many jobs running simultaneously on the cluster. However, Mesos itself doesn’t have a notion of a job. It only cares about frameworks and individual tasks that those frameworks want to schedule.
Another important detail is how Mesos achieves task isolation and enforces resource constraints. As in, how does Mesos ensure a task only uses the resources it was allowed to use? And how does it keep tasks from interfering with each other? The answer to both of these questions is linux containers. When the original paper was published, this meant plain LXC. There is also mention of Solaris Projects for the Solaris operating system. Soon after the release of Mesos, it started supporting the fancier version of plain LXC: Docker containers. Still today, Mesos uses Docker containers to isolate tasks from each other and monitor as well as contrain their resource usage. Rkt is also supported.
Note that Mesos agents used to be called “slaves”. “Slave” is now outdated terminology and deprecated in favor of “agent”.
Framework Interfaces
The second part of the Mesos architecture is the stubs it leaves for frameworks to plug in. Remember that Mesos leaves the scheduling as well as execution (launch) of tasks to frameworks themselves. As such, in order to run a framework on Mesos, you need to implement a scheduler and an executor.
Scheduler
The scheduler is the component that receives resource offers from Mesos (more on this in a bit) and decides how many tasks to launch using those resources. This would effectively be a wrapper around the YARN scheduler for Hadoop for example. The scheduler is also responsible for responding to failures of any tasks that it launched. Hadoop might want to re-schedule such a failed task.
Executor
A framework’s executor is responsible for launching a task and updating its state. This could literally just be a thin shell script that starts a binary, but it could just as well be a complex application that starts a thread for a new task rather than a new process. The executor must also communicate the status and health of the task to the Mesos agent, so that the agent can in turn notify the Mesos master and framework scheduler of task completion or failure.
As far as I understand, there can be executors from multiple frameworks running on the same machine, but there will only be one Mesos agent per host.
Behavior
Having described the components in a typical Mesos cluster, we need to discuss in more detail how those components behave and interact. First, we’ll go over the API that Mesos exposes on masters and agents, schedulers and executors. Then, we’ll dive deeper into what a resource offer actually is. Lastly, I want to touch upon the allocation algorithm that Mesos uses to decide which framework gets which resources.
APIs
I care to discuss the API Mesos provides because it gives a good overview of the way Mesos interacts with its agents as well as indidvidual frameworks. The API here refers to remote procedure calls (RPCs) frameworks can make to the Mesos master and agents and vice versa. More precisely, the API is split into four parts:
- The methods a framework’s scheduler must implement so that the Mesos master can call them (callbacks),
- The methods a framework’s scheduler can call on the Mesos master (actions),
- The methods a framework’s executor must implement so that the Mesos agent can call them (callbacks),
- The methods a framework’s executor can call on the Mesos agent (actions),
Table I from the paper summarizes these API calls:

Let’s touch upon them individually.
Scheduler Callbacks
These are methods a framework must implement to respond to the Mesos master, which makes these API calls.
resourceOffer(offerId, offers): Called by the Mesos master to offer the framework a collection of resources.
offerRescinded(offerId): Called by the Mesos master to indicate that a previous offer it made (via resourceOffer) is no longer valid. This could be because the framework scheduler took too long to respond, so the Mesos master wants to offer the resources to another framework.
statusUpdate(taskId, status): Called by the Mesos master when it receives an updated status for one of the framework’s tasks from a Mesos agent. For example, it could indicate that a task failed.
slaveLost(slaveId): Called by the Mesos master when a whole machine appears to have gone down in the cluster.
It is up to frameworks to decide what to do with the information conveyed by these API calls.
Scheduler Actions
These are methods already implemented on the Mesos master side, that a framework can invoke.
replyToOffer(offerId, tasks): Called by a framework to give the Mesos master tasks the framework wants to schedule using the resources provided in a previous resourceOffer(). The framework itself decides how many tasks to schedule based on a group of resources.
setNeedsOffers(bool): Called by a framework to indicate it urgently needs resource offers to schedule more tasks.
setFilters(filters): Called by a framework to provide the Mesos resource offer allocator boolean filters it can use to pre-filter offers for that framework. This allows a framework to provide scheduling constraints. For example, a framework may want to filter out any offers with less than 4 CPUs or 1GB of RAM.
getGuaranteedShare(): This one is a bit mysterious. There’s no mention of it in the paper, and Mesos’ GitHub repository shows no reference to it either. I think it was part of a mechanism where a framework could be guaranteed a fixed (static) share of resources, maybe the minimum number of resources it needs to run at all (to run its own master and auxiliary services).
killTask(taskId): Called by a framework to kill a particular running task.
Executor Callbacks
These are API calls the Mesos agent will make on a framework’s executor. A framework must implement these methods in its executor component.
launchTask(taskDescriptor): Called by a Mesos agent for each task that was scheduled by a framework’s scheduler to run on this node. The task descriptor would be whatever data the executor needs to launch a task.
killTask(taskId): Called by a Mesos agent to kill a particular task. For example, it could be on behalf of the framework scheduler itself when it calls killTask() on the Mesos master.
Executor Actions
These are methods a framework’s executor can call on the Mesos agent running on its machine.
sendStatus(taskId, status): Updates the Mesos agent (and in turn, the rest of the system) about the status of a particular task.
Resource Offers
One of the scheduler callbacks we touched upon above was
resourceOffer(offerId, offers), which the Mesos master calls on a framework’s
scheduler to offer it resources. But what exactly is that second parameter,
offers? What exactly is a resource offer? As the age-old idiom goes:
A snippet of code is worth a thousand words.
So let’s take a look at the code. From mesos.proto:
/**
* Describes some resources available on a slave. An offer only
* contains resources from a single slave.
*/
message Offer {
required OfferID id = 1;
required FrameworkID framework_id = 2;
required SlaveID slave_id = 3;
...
repeated Resource resources = 5;
...
Besides information to identify the offer, the agent (slave) on which resources are available and the target framework to which resources are offered, we see
repeated Resource resources = 5;
a list of resources! The
Resource proto
is a bit large, but essentially it describes a quantity of some resource. For
example, 4GB of RAM or 8 CPUs.
A framework’s scheduler gets offered this list of resources and then decides how many tasks to schedule using those resources. Note that a resource offer always corresponds to a single host (a single agent).
Resource Allocation
The last bit of detail I want to talk about is how the Mesos master decides which resources to offer to which framework. After all, this seems like it would be one of the most critical decisions! The paper does not delve too deeply into this topic and takes it somewhat for granted. I did some additional research and want to outline the algorithm Mesos uses by default. Note that you can swap out this algorithm for a different one if you need or want to.
Let’s take a step back. What problem are we talking about here? The problem we are talking about is that there are many frameworks competing for resources in our cluster. Of course, each framework would ideally like to have the whole cluster to itself, but that is not quite the point of Mesos.

The point of Mesos is to share resources among frameworks in a way that keeps utilization of the cluster high and gives each framework a fair share of resources. The algorithm Mesos uses for this is called Dominant Resource Fairness or DRF for short. It was developed by many of the same authors as the Mesos paper. The DRF paper is itself worth a sweep as it delves into interesting topics such as game theory and how to fairly divide resources among contestants.
In short, the way DRF works is that it tries maximize the smallest dominant share among all frameworks. The dominant share is the share a framework has of the resource it demands the most. This resource is termed the dominant resource.
Example
Take a cluster with 10 CPUs and 10 GB of RAM available in total (among all machines). Two frameworks are running on this cluster using Mesos. Their resource shares are currently distributed as follows:
| Framework | Number of Tasks | CPUs | RAM |
|---|---|---|---|
| A | 2 | 4 | 2 |
| B | 3 | 1 | 3 |
Let’s first determine the dominant resources and shares. Framework A’s dominant resource is CPU, since that is the resource for which its share is the largest. Framework B’s dominant resource is RAM. Framework A’s dominant share is 40%, because its share of its dominant resource is 40%. Framework B’s dominant share is 30%, because it has 3 out of 10 GB of RAM.
Say Mesos now wants to offer 2 CPUs and 2 GB of RAM as part of a single resource
offer. If it gave it to A, it would have 6 CPUs and 4 GB of RAM and its dominant
share would be 60%. If it instead supplied it to framework B, it would have 3
CPUs and 5 GB of RAM and its dominant share would be 50%. Since the other
framework’s share would stay as shown in the table above, the DRF algorithm
would choose to offer the resources to framework B. This is because dominant shares
of (40%, 50%) have a larger minimum (40%) than (60%, 30%) as would have been the
case if framework A had gotten the offer.
See this article for more in-depth information on DRF in the context of Mesos.
Apache Aurora
I hope that by now you have a reasonably well founded understanding of how Mesos works. Before we conclude this sweeping tour of Mesos, I want to talk about one project built on top of Mesos that deserves mention: Apache Aurora.
In the project’s own words, “Aurora is a Mesos framework for long-running services and cron jobs”. There are two important parts to this sentence. The first is that Aurora is meant for long-running services. A typical example of this are microservices as they are used to power much of modern backend infrastructure. This is relevant because Mesos itself was more targeted towards cluster frameworks that launch many small, short lived tasks such as Hadoop. However, there is also nothing that fundamentally stands in the way of long running jobs running Mesos. Where Aurora does improve on bare Mesos for this is that it has better support for managing, monitoring and updating long running jobs. The second important part of that summary is that Aurora is a Mesos framework. That is, it’s integrated into Mesos with exactly the interfaces and hooks we have described so far.
So what does Aurora exactly provide? If you’ve ever heard of Google’s Borg, Facebook’s Tupperware or the Kubernetes project, you can think of Aurora on Mesos as an alternative to these. It is a service-oriented cluster management framework used by Twitter and Uber for all of their service orchestration. It does things such as:
- Managing resource quotas for different services,
- Supporting updating services (new configuration or binary releases),
- Providing service discovery to enable services to talk to each other.
Aurora also has a fancy domain-specific language (DSL) to describe job configuration as well as complex scheduling constraints, such as requiring two tasks to be co-located on the same machine.
One interesting thing to note here is that often times, Aurora will be the only framework running on a Mesos cluster. In some sense this is peculiar, since Mesos was really conceived to allow many frameworks to run on the same cluster. However, Mesos simply provides an excellent better-than-starting-from-zero platform for running resource-isolated tasks on a cluster of machines. Things like built-in support for health checks and failure detection make it easier to build something like Aurora on top of it than having to build these features from scratch.
See this StackOverflow question to learn about the difference between Apache Aurora and Kubernetes.
Conclusion
This article gave a sweeping tour of Apache Mesos, a cluster management library that enables multiplexing many cluster frameworks on a shared pool of compute resources. My goal with this blog post was to provide an easier, more condensed read than the original paper is and extend it with detail where more detail was necessary or interesting to add. I also touched upon Apache Aurora, one of the largest, most useful and full-fledged projects built on top of Apache Mesos.
I hope this article was useful to you!
